
How does Google Crawling and Indexing Work?
![]()
When you make a search query in a search engine, the search engine must have already found the pages to be shown in the results. This happens when software robots, known as spiders, crawl the web to find new and updated web pages.
So how does this process work?
Think of it as flipping through a college textbook while studying for a test. You find the most important chapters, then scan towards the sections to find the relevant pages to study.
Google Spiders (Bots)
Like this, the spiders usually begin with heavily used servers and the most popular pages and from there, will index the words on each page. Next, they will follow each link that is found on the site.
This process allows the automated bots to place each page in an authoritative order and to place them in categories relevant to user searches.
Next, these spiders take note of all the words used and where these words are placed on a site.
This placement determines the relevance and importance of each word. These words can be contained in a link, header, title, list, or paragraph.
What does the Header, Paragraph, and Link Tags Look Like?
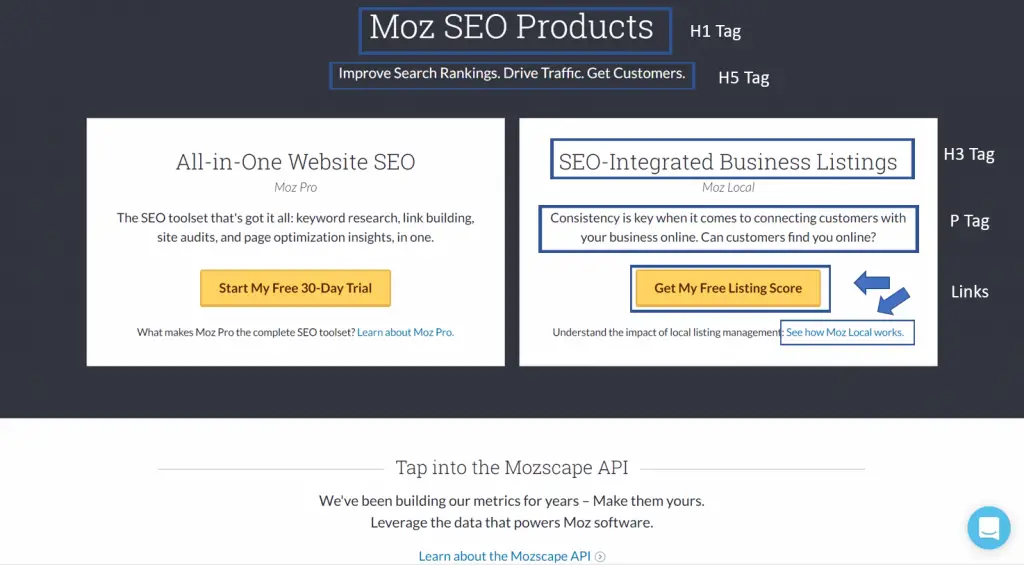
For example, let’s look at the products page of Moz.com.
Here we can see some of the elements and how a certain keyword is placed within them. Presumably, it can be determined that the words SEO, Moz, business, listing, and customers are common keywords the website is looking to include in their rankings.
Other keywords are strategically placed in these elements as well including terms such as search rankings, traffic, and toolset.
So, how do the search engine spiders crawl the world wide web?
The main way these automated robots can move around the web is through the link structure which binds all the pages together.
This is how search engines can search and index billions of pages that a user can access at the fraction of a second. Therefore, it is crucial to have an organized and well thought out linking structure to any website so the spiders can crawl them correctly for relevance.
Once the spiders crawl through the links, they analyze the content and build an index of terms for each page. This indexing goes into a massive database to contain all significant terms on each page crawled by the search engine.
The next step in the process occurs when the search engine returns a list of relevant web pages in the order that they feel will most likely prove to satisfy the searcher.
First, the search engine explores the hundreds of billions of pages to only return relevant results paired with a search query and then ranks the pages based on perceived importance.
This can be due to strong SEO efforts and the trust and authority of a given website. The key ingredients for ranking well with a website is relevance and importance.
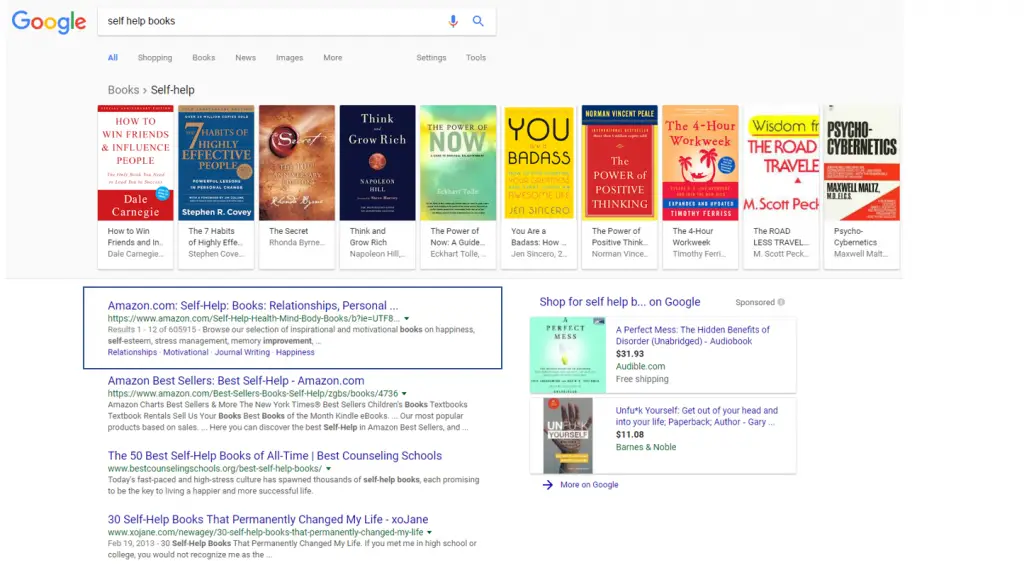
So, when we search “self-help books” into the Google search engine, the top result ends up at the Amazon self-help book section. This tells us that this web page has the highest combined score of relevance and importance for that search query.

These factors are not determined manually by the search engines as that would take trillions of man-hours to complete such a task.
That is why search engines such as Google use complex algorithms to sort out web pages based on quality. These algorithms are made up of many components that are referred to as ranking factors.
These factors will be discussed more in detail in a later video. It’s the improvement upon the relevance and importance of web pages that are the basics of search engine optimization.
Check out our services offered at Animas Marketing to learn more about the wonderful world of SEO or get started on your own with our free guide below.
Download the Ultimate Guide for Local Business
Enjoy this free resource from us to help you learn the essential techniques to boost your rankings on search engines.

Is Your Business Being Found Online?
Free Ultimate SEO Guide for Local Business ($40 value)
![]() Learn the easiest optimization techniques that most marketing agencies don’t want you to know about.
Learn the easiest optimization techniques that most marketing agencies don’t want you to know about.
Need Marketing Help?
If you want assistance with marketing strategies to grow your business, then let’s talk.
0 Comments